
NeeNetです。
今回はAWS環境でAmazon EMRを用いて、Apache Sparkを実行してみたいと思います。
はじめに
Amazon EMRとは
Amazon EMR(Elastic MapReduce)は、AWSが提供するマネージドクラウドサービスで、Hadoop, Spark, HBaseなどのビッグデータフレームワークを簡単に実行できるサービスです。
インフラストラクチャのプロビジョニング、設定、スケーリングを自動化し、データ処理や分析、機械学習のワークロードを効率的に実行することができます。
Apache Sparkとは
Apache Sparkは高速な分散処理エンジンです。
具体的には以下の特徴があります。
- 統合分析エンジン(バッチ処理、ストリーミング、SQL、機械学習)
- 複数言語API(Java、Scala、Python、R)
- DataFrames/Datasetsによる構造化データ処理
- MLlibによる機械学習機能
特にPySpark(Python用Spark API)は、Pythonの使いやすさとSparkの処理能力を組み合わせ、大規模データセットの効率的な分析を可能にします。
事前準備
データの準備
まず、今回使うデータの用意を行います。
今回は「MovieLens」というデータセットを使います。(MovieLensデータセットは映画作品レビューサイトの作品評価データです)
こちらのページから、「MovieLens Latest Datasets」の「ml-latest-small.zip」をダウンロードします。

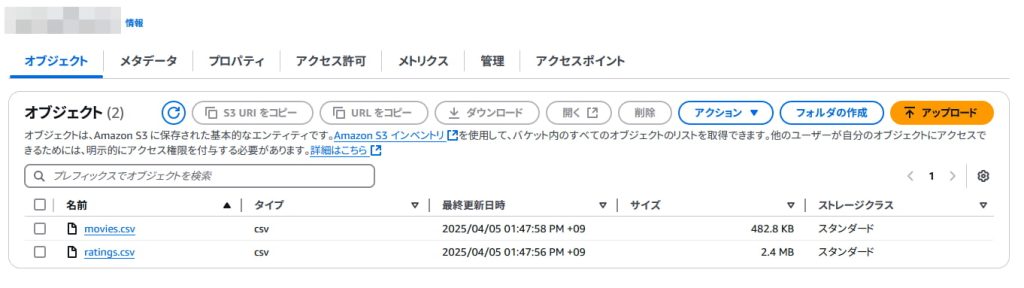
ダウンロードしたファイルを展開するとcsvファイルがいくつか入っていると思いますが、その中で movies.csv と ratings.csv をS3バケットにアップロードします。
Pythonファイルの準備
続いて、今回EMRで動かすPythonファイルを作成します。
movies.csv と ratings.csv を読み込んで、それぞれ10件ずつ表示する以下プログラムを作成してみます。
import sys
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.types import *
if len(sys.argv) != 3:
print("Usage: movies <moviespath> <ratingspath> ", file=sys.stderr)
exit(-1)
spark = SparkSession.builder.appName('MovieLens').getOrCreate()
spark.sparkContext.setLogLevel("WARN")
schema_movies = StructType(
[
StructField("movieId", StringType(), False),
StructField("title", StringType(), False),
StructField("genres", StringType(), True),
]
)
schema_ratings = StructType(
[
StructField("userId", StringType(), False),
StructField("movieId", StringType(), False),
StructField("rating", FloatType(), True),
StructField("timestamp", StringType(), True),
]
)
file_path_movies = sys.argv[1]
file_path_ratings = sys.argv[2]
movies = (
spark.read.format("csv")
.option("encoding", "UTF-8")
.option("header", True)
.option("sep", ",")
.option("escape", '"')
.schema(schema_movies)
.load(file_path_movies)
)
movies.show(10)
ratings = (
spark.read.format("csv")
.option("encoding", "UTF-8")
.option("header", True)
.option("sep", ",")
.option("escape", '"')
.schema(schema_ratings)
.load(file_path_ratings)
)
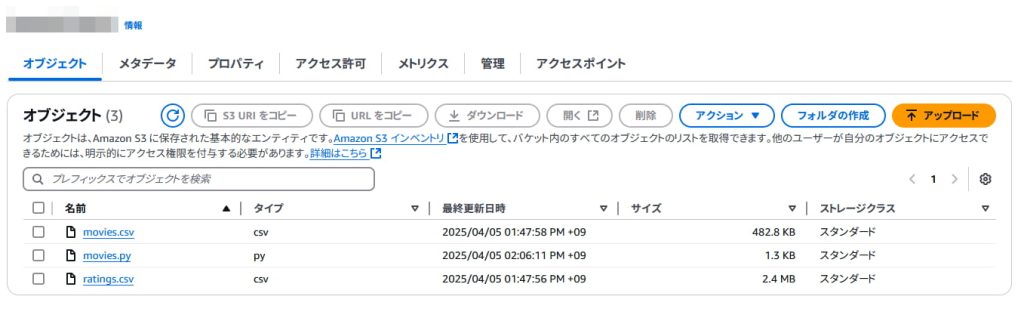
ratings.show(10)作成した movies.pyを先程と同じS3バケットに配置します。
これで事前準備は完了です。
Amazon EMRの起動
それでは、Amazon EMRを起動します。
Amazon EMRのサービスから『クラスターを作成』のページへ遷移し、アプリケーションバンドルとして『Spark Interactive』を選択します。
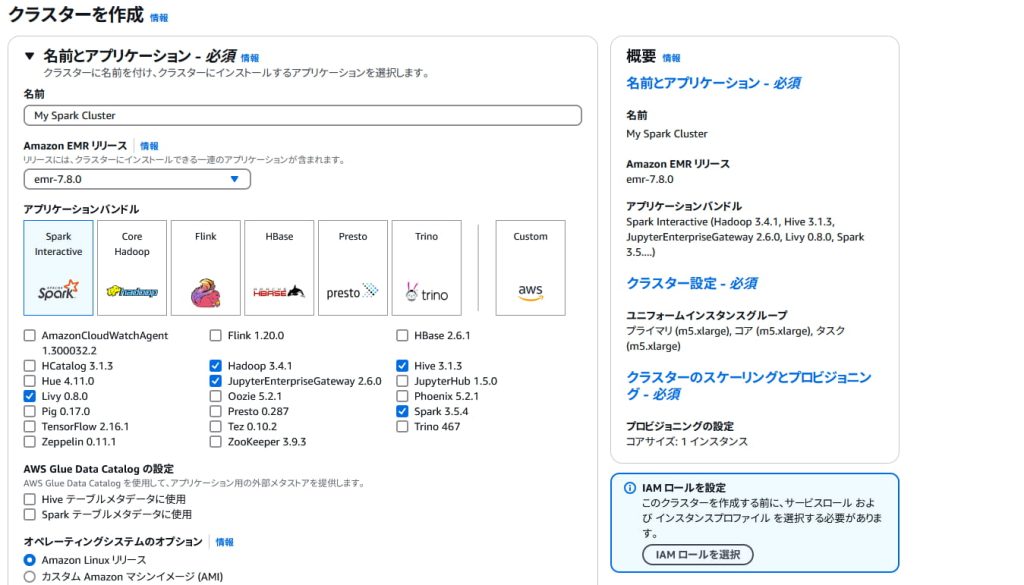
VPCやサブネットについては、ご自身の環境のものをご指定ください。
プライマリーノードのセキュリティグループには、インターネットからのSSH(22番ポート)への通信を許可したものを追加しておきます。

EMRのサービスロールにはマネージドポリシーである「AmazonEMRServicePolicy_v2」ポリシーをアタッチしたロールを選択し、EMRのEC2インスタンスプロファイルにはマネージドポリシーである「AmazonS3FullAccess」ポリシーをアタッチしたロールを選択します。
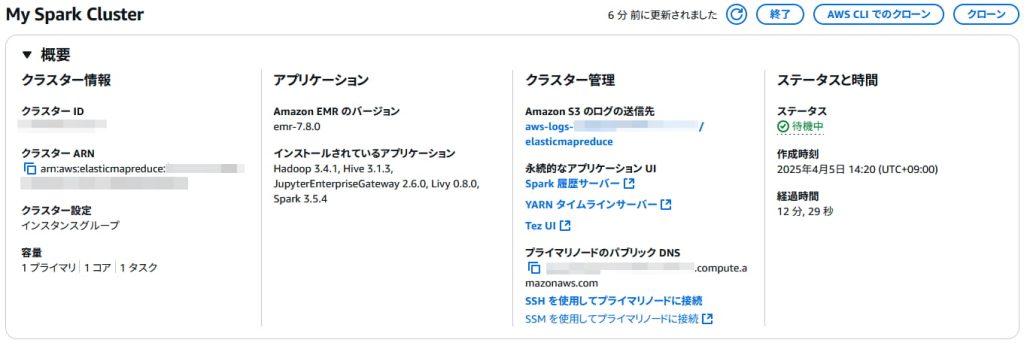
ここまでできたらクラスターを作成します。
以下のように起動すれば成功です。
Amazon EMRへの接続
EMRが起動できたら、SSHを用いてプライマリーノードに接続します。
$ ssh -i ./emr-key-pair.pem hadoop@ec2-00-000-000-000.us-east-2.compute.amazonaws.comhadoop@ 後ろ部分の接続先については、起動したEMRのパブリックDNSを設定してください。
接続に成功すると、以下のような画面になると思います。
S3からEMRプライマリーノードへのファイルダウンロード
以下のコマンドで、先程S3にアップロードしたPythonファイルをEMRのプライマリーノードへダウンロードします。
$ aws s3 cp s3://<BUCKET-NAME>/movies.py /home/hadoop/movies.py※ <BUCKET-NAME> の部分はご自身の環境に合わせてください。
Sparkの実行
Pythonファイルのダウンロードが完了したら、以下の通りSparkを実行します。
$ spark-submit --deploy-mode client --master yarn movies.py s3://<BUCKET-NAME>/movies.csv s3://<BUCKET-NAME>/ratings.csv※ <BUCKET-NAME> の部分はご自身の環境に合わせてください。
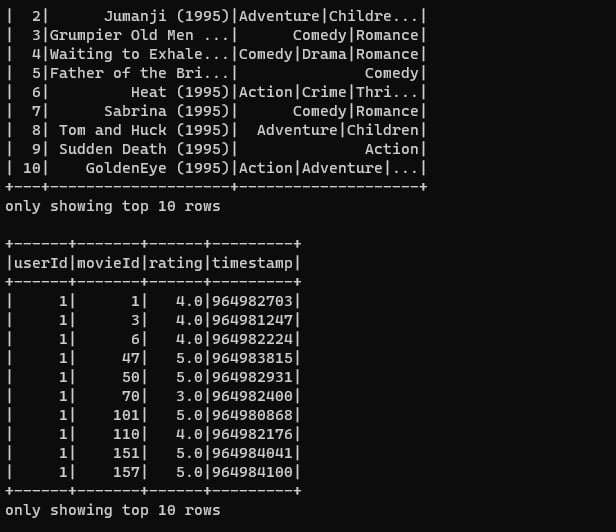
以下の通り、 movies.csv と ratings.csv の上位10件のデータがそれぞれ表示されていれば成功です。
先ほどの movie.py を一部改修し、映画毎のレビュー数をカウントし、降順に並べるプログラムにしてみます。
import sys
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import col, count, desc
if len(sys.argv) != 3:
print("Usage: movies <moviespath> <ratingspath> ", file=sys.stderr)
exit(-1)
spark = SparkSession.builder.appName('MovieLens').getOrCreate()
spark.sparkContext.setLogLevel("WARN")
schema_movies = StructType(
[
StructField("movieId", StringType(), False),
StructField("title", StringType(), False),
StructField("genres", StringType(), True),
]
)
schema_ratings = StructType(
[
StructField("userId", StringType(), False),
StructField("movieId", StringType(), False),
StructField("rating", FloatType(), True),
StructField("timestamp", StringType(), True),
]
)
file_path_movies = sys.argv[1]
file_path_ratings = sys.argv[2]
movies = (
spark.read.format("csv")
.option("encoding", "UTF-8")
.option("header", True)
.option("sep", ",")
.option("escape", '"')
.schema(schema_movies)
.load(file_path_movies)
)
ratings = (
spark.read.format("csv")
.option("encoding", "UTF-8")
.option("header", True)
.option("sep", ",")
.option("escape", '"')
.schema(schema_ratings)
.load(file_path_ratings)
)
# movieIdでグループ化し、各映画に関連付けられたユーザー数をカウント
review_counts = ratings.groupBy("movieId").agg(count("userId").alias("num_ratings"))
# 列名をnum_ratingsに変更し、その列で降順に並べ替え
sorted_review_counts = review_counts.orderBy(desc("num_ratings"))
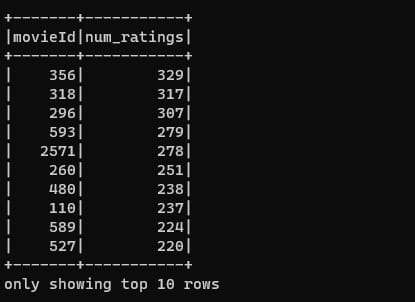
sorted_review_counts.show(10)上記プログラムを先程と同じコマンドで実行すると、結果は以下のようになります。
今回はMovieLensの中でもサンプルとなる小規模なデータセットを利用していますが、データ数が多いより大規模なデータになってくると、Sparkの分散処理が効果的になってきます。
最後に
今回はAmazon EMRでApache Sparkを実行してみました。
参考になりましたら幸いです。
ご依頼について

NeeNetではAWSを利用したインフラ環境やデータ分析基盤の構築のご依頼・ご相談をお引き受けしております。
個人・法人問わず、何かご相談事項がございましたら、一度ご連絡いただければと思います。