
NeeNetです。
今回はPythonのモジュールであるkeras_efficientnetでファインチューニングを行い、Grad-CAMを適用して予測根拠を可視化してみたいと思います。
環境
今回、実行を行った環境は以下の通りです。
| OS | Windows 11 Pro |
| GPU | GeForce RTX 3060 Ti |
| Pythonのバージョン | 3.10.13 |
| 主要モジュールのバージョン | keras-efficientnets==0.1.7 tensorflow-gpu==2.10.1 |
また、今回のフォルダ構成は以下の通りです。
.
├ dataset
│ ├ test
│ │ ├ homura
│ │ │ ├ homura_01.jpg
│ │ │ └ xxx.jpg
│ │ ├ kyoko
│ │ └ ...
│ └ train
│ ├ homura
│ │ ├ homura_01.jpg
│ │ └ xxx.jpg
│ ├ kyoko
│ └ ...
├ image_val
│ ├ homura_val_01.jpg
│ └ xxx.jpg
├ finetune.py
└ gradcam.pydatasetにはtrainフォルダとtestフォルダを用意し、その中で更に特定クラスの画像をまとめたフォルダを作成、その中に画像ファイルを保存します。
今回はEfficientNetB4をファインチューニングし、「魔法少女まどか☆マギカ」に出てくるキャラクターを分類するモデルを作成したいので、train/testフォルダはそれぞれ homura, kyoko, madoka, mami, sayaka というフォルダを作成し、その中に各キャラクターの画像を格納しています。
また、Grad-CAMを適用する画像はimage_valフォルダに直接画像を格納します。
finetune.pyとgradcam.pyは今回作成するpythonプログラムのため、後ほど記載します。
ファインチューニングを行う
今回使用するkeras_efficientnetsは、pipを用いて以下でダウンロードすることができます。
$ pip install keras-efficientnet 早速ですが、finetune.pyの中身は以下の通りです。
import glob
import os
import matplotlib.pyplot as plt
import numpy as np
from keras.callbacks import EarlyStopping, ReduceLROnPlateau, TensorBoard
from keras.layers import BatchNormalization, Dense, Dropout, GlobalAveragePooling2D
from keras.models import Model
from keras.optimizers import Adam
from keras.utils.np_utils import to_categorical
from keras_efficientnets import EfficientNetB4
from PIL import Image
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# クラス取得
classes = os.listdir("./dataset/train")
# クラス数
num_classes = len(classes)
# 画像サイズ
image_size = 380
input_shape = (image_size, image_size, 3)
# lossの設定
if num_classes > 2:
loss_type = "categorical_crossentropy"
else:
loss_type = "binary_crossentropy"
# 画像を取得し、配列に変換
def im2array(path):
X = []
y = []
class_num = 0
for class_name in classes:
if class_num == num_classes:
break
imgfiles = glob.glob("{0}/{1}/*".format(path, class_name))
for imgfile in imgfiles:
# 画像読み込み
image = Image.open(imgfile)
# RGB変換
image = image.convert("RGB")
# リサイズ
image = image.resize((image_size, image_size))
# 画像から配列に変換
data = np.asarray(image)
X.append(data)
y.append(classes.index(class_name))
class_num += 1
X = np.array(X)
y = np.array(y)
return X, y
# trainデータ取得
X_train, y_train = im2array("./dataset/train")
# testデータ取得
X_test, y_test = im2array("./dataset/test")
# データ型の変換
X_train = X_train.astype("float32")
X_test = X_test.astype("float32")
# 正規化
X_train /= 255
X_test /= 255
# one-hot 変換
y_train = to_categorical(y_train, num_classes=num_classes)
y_test = to_categorical(y_test, num_classes=num_classes)
# trainデータからvalidデータを分割
X_train, X_valid, y_train, y_valid = train_test_split(
X_train, y_train, random_state=0, stratify=y_train, test_size=0.2
)
# data augmentation
datagen = ImageDataGenerator(
featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
vertical_flip=False,
)
# EarlyStopping
early_stopping = EarlyStopping(
monitor="val_loss", patience=10, min_delta=0, mode="auto", verbose=1
)
# reduce learning rate
reduce_lr = ReduceLROnPlateau(
monitor="val_loss",
factor=0.1,
patience=10,
mode="auto",
epsilon=0.0001,
cooldown=0,
min_lr=0,
verbose=1,
)
# モデル学習
def model_fit():
hist = model.fit_generator(
datagen.flow(X_train, y_train, batch_size=4),
steps_per_epoch=X_train.shape[0] // 4,
epochs=25,
validation_data=(X_valid, y_valid),
callbacks=[early_stopping, reduce_lr],
shuffle=True,
verbose=1,
)
return hist
# モデル保存
def model_save():
model_dir = "./model"
if os.path.exists(model_dir) == False:
os.mkdir(model_dir)
model_path = os.path.join(model_dir, "finetune_model")
if not os.path.exists(model_path):
os.makedirs(model_path)
model.save(model_path)
# 学習曲線をプロット
def learning_plot(title):
plt.figure(figsize=(18, 6))
# accuracy
plt.subplot(1, 2, 1)
plt.plot(hist.history["accuracy"], label="accuracy", marker="o")
plt.plot(hist.history["val_accuracy"], label="val_accuracy", marker="o")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.title(title)
plt.legend(loc="best")
plt.grid(color="gray", alpha=0.2)
# loss
plt.subplot(1, 2, 2)
plt.plot(hist.history["loss"], label="loss", marker="o")
plt.plot(hist.history["val_loss"], label="val_loss", marker="o")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.title(title)
plt.legend(loc="best")
plt.grid(color="gray", alpha=0.2)
plt.show()
# モデル評価
def model_evaluate():
score = model.evaluate(X_test, y_test, verbose=1)
print("evaluate loss: {[0]:.4f}".format(score))
print("evaluate acc: {[1]:.1%}".format(score))
# xception
base_model = EfficientNetB4(
include_top=False, weights="imagenet", input_shape=input_shape
)
# 全結合層の新規構築
x = GlobalAveragePooling2D()(base_model.output)
x = BatchNormalization()(x)
# 間にDropoutを追加すると性能が上がる場合がある
x = Dropout(0.5)(x)
output = Dense(num_classes, activation="softmax", name="last_output")(x)
# ネットワーク定義
model = Model(inputs=base_model.input, outputs=output, name="model")
print("{}層".format(len(model.layers)))
# 109層までfreeze
for layer in base_model.layers[:109]:
layer.trainable = False
# モデルのcompile
model.compile(
optimizer=Adam(learning_rate=0.0001), loss=loss_type, metrics=["accuracy"]
)
hist = model_fit()
learning_plot("EfficientNetB4")
model_evaluate()
model_save()
今回はファインチューニングを行うため、EfficientNetB4 のモデルのロード時にinclude_top=False を設定し、全結合層を取得しないようにしています。
その後、今回のクラス分類タスク用の全結合層を追加しています。
転移学習とファインチューニングの違い
転移学習とファインチューニングはざっくりと以下のように区別することができます。
転移学習
転移学習では、一般的には大規模データセット(例えばImageNet)で事前に訓練されたモデルの重みを初期値として使用し、その上で新たなタスクに対する出力層を追加し、その出力層のみを学習します。
この手法は新たなデータセットが小さく、データ不足による過学習を防ぐのに有用です。
転移学習では、基本的にはpre-trainingの段階で獲得した特徴抽出器を変えることはありません。
ファインチューニング
ファインチューニングでは、転移学習と同様に事前に訓練されたモデルの重みを使用しますが、新たなタスクの学習時に全てのレイヤーの重みを調整(=再訓練)します。
これは新たなタスクのデータセットが大きく、元のタスクでやっていたこととの違いが大きい場合に有効です。
以上を踏まえ、ざっくりとまとめると以下の通りです。
転移学習
新たに追加された出力層のみを学習する
ファインチューニング
モデルの全体、または一部を学習する
今回はファインチューニングであり、かつ入力層に近い層の学習は不要と考え、472層の内109層までは学習しないように設定(Freeze)しています。
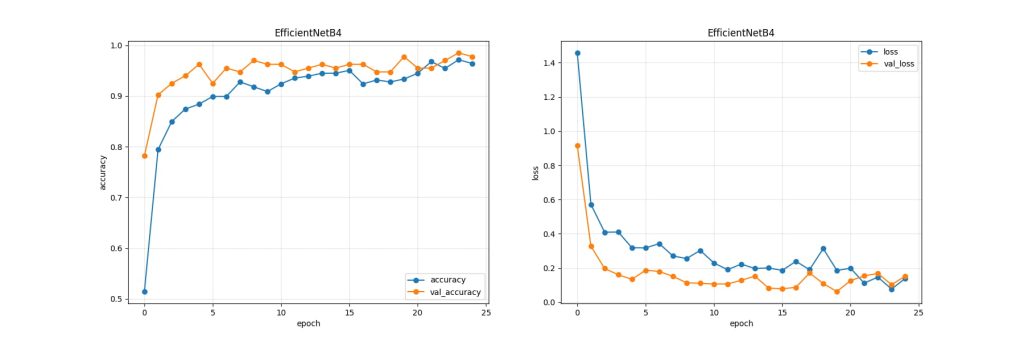
学習結果
学習の結果は以下の通りです。
evaluate loss: 0.0379
evaluate acc: 97.3%テストデータに対する正解率が 97.3% と高い結果になりました。
学習曲線は以下の通りです。
Grad-CAMで予測根拠を可視化
Grad-CAM(Gradient-weighted Class Activation Mapping) は、畳み込みニューラルネットワーク (CNN) において、分類の際にどこに注目したのかの解釈可能性を高めるための手法です。
Grad-CAMは入力画像中の特定の領域が最終的な出力にどれだけ影響を与えているかを、色の濃淡で表現します。
濃い色であればネットワークがその領域を強く参照していることを示し、淡い色はそうでない領域として示すことができます。
gradcam.pyは以下の通りです。
import glob
import os
import cv2
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from keras.models import Model, load_model
from keras_efficientnets.efficientnet import preprocess_input
from PIL import Image
from tensorflow import keras
from tensorflow.keras.preprocessing import image as kimage
# 画像サイズ
image_size = 380
def apply_gradcam(model, img, layer_name):
original_img = kimage.img_to_array(img)
img = img.resize((image_size, image_size))
img_array = kimage.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array = preprocess_input(img_array)
# レイヤーを取得
target_layer = model.get_layer(layer_name)
# 予測クラスの取得
prediction = model.predict(img_array)
prediction_idx = np.argmax(prediction)
print("prediction:", prediction)
print("prediction_idx:", prediction_idx)
# 予測されたTopのクラスのGradientを計算
with tf.GradientTape() as tape:
gradient_model = Model([model.inputs], [target_layer.output, model.output])
conv2d_out, prediction = gradient_model(img_array)
# Prediction Lossの取得
loss = prediction[:, prediction_idx]
# conv_outputに対する損失の勾配を取得
gradients = tape.gradient(loss, conv2d_out)
# Shape [1 x H x W x CHANNEL] -> [H x W x CHANNEL]から出力を取得
output = conv2d_out[0]
# 勾配を空間的に平均化する
weights = tf.reduce_mean(gradients[0], axis=(1, 2))
activation_map = np.zeros(output.shape[0:2], dtype=np.float32)
# layerごとにweightを乗算する
for idx, weight in enumerate(weights):
activation_map += weight * output[:, :, idx]
# 元画像のサイズにリサイズを行う
activation_map = cv2.resize(
activation_map.numpy(), (original_img.shape[1], original_img.shape[0])
)
# 負の数をなくす
activation_map = np.maximum(activation_map, 0)
max_val = activation_map.max()
min_val = activation_map.min()
# Activation Mapを0 - 255に変換
if max_val - min_val == 0:
activation_map = np.zeros_like(activation_map)
else:
activation_map = (activation_map - min_val) / (max_val - min_val)
activation_map = np.uint8(255 * activation_map)
# heatmapに変換
heatmap = cv2.applyColorMap(activation_map, cv2.COLORMAP_JET)
original_img = np.uint8(
(original_img - original_img.min())
/ (original_img.max() - original_img.min())
* 255
)
cvt_heatmap = cv2.cvtColor(heatmap, cv2.COLOR_BGR2RGB)
# heatmapと元画像を重ねる
result = np.uint8(original_img * 0.5 + cvt_heatmap * (1 - 0.5))
return result
def run_on_image(model, layer_name, image_path, output_dir):
img = Image.open(image_path).convert("RGB")
# heatmapと元画像が重なった画像を取得
result = apply_gradcam(model, img, layer_name)
# 結果を保存
result_path = os.path.join(
output_dir, f"{os.path.basename(image_path)}_gradcam.jpg"
)
plt.rcParams["figure.dpi"] = 100
plt.imsave(result_path, result)
if __name__ == "__main__":
input_dir = "image_val"
output_dir = "image_result"
model = load_model("./model/finetune_model", compile=False)
# GradCAMの対象レイヤー(最後のConv2Dレイヤー)を取得
last_conv_layer = next(
x for x in model.layers[::-1] if isinstance(x, keras.layers.Conv2D)
)
target_layer_name = last_conv_layer.name
if not os.path.exists(output_dir):
os.mkdir(output_dir)
image_paths = glob.glob(f"{input_dir}/*.jpg")
for image_path in image_paths:
print(f"Processing {image_path}")
run_on_image(model, target_layer_name, image_path, output_dir)
冒頭の環境セクションで述べた通り、image_valフォルダ内の画像を読み込み、Grad-CAMを適用した結果をimage_resultフォルダに出力する形となっています。
なお、Grad-CAMを適用するターゲットの層はConv2Dの最終層としています。
アルゴリズムについてより詳しく知りたい方は原著論文をご確認ください。
Grad-CAMの適用結果
まず、ほむらの画像の出力結果を見てみます。


見て明らかな通り、目に注目していることが分かります。顔がドアップの画像となっているので、着目点としては正しいのかも知れません。
ちなみに予測結果も正解でした。
次に、杏子の出力結果を見てみます。


こちらは顔全体に着目していることが分かります。こちらも予測結果は正解でした。
最後に、マミの出力結果を見てみます。


こちらは顔全体と衣装の一部に着目していることが分かります。このように可視化できると面白いですね!
こちらの画像についても予測結果は正解でした。
最後に
今回はPythonのモジュールであるkeras_efficientnetでファインチューニングを行い、Grad-CAMを適用して予測根拠を可視化してみました。
ファインチューニングは既に学習がなされた高性能なモデルを流用し、自分自身が行いたいタスクに流用するための有効な手法です。
またGrad-CAMを使えば予測根拠も可視化することができるので、例えば「肺に問題があるか否か」というようなタスクに対し問題があるとAIが判定した場合、それはどこに着目した結果かを確認することで医療における画像判定に活用できたりするかも知れません。
ご依頼について

NeeNetではPythonを用いた機械学習案件のご依頼・ご相談をお引き受けしております。
個人・法人問わず、何かご相談事項がございましたら、一度ご連絡いただければと思います。
ご依頼は下記のお問い合わせページから可能です。