
概要
PythonとTesseract OCRを用いて、伝票番号を自動で読み取り、csvファイルに出力するプログラムを作成させて頂きました。
読み取る伝票は下記の様になっています。

依頼背景
ご依頼者様の会社では、これまで伝票番号をcsvに手入力していたそうです。
ただ、結構その作業に時間がかかっていたらしく、この度作業自動化&効率化を目的にプログラムで自動化させたいとのことでした。
今回はPythonの環境をご用意しているとのお話だったので、PythonとGoogle社のTesseract OCRを使って当該作業を自動化するプログラムを作成することにしました。
プログラムの処理手順と結果
プログラム内での具体的な処理手順は下記の通りです。
- 伝票画像の読み込み
- 黒っぽい色以外は白にする画像変換
- 伝票番号部分の切り取り
- OCRの実行(ここでTesseract OCRを使用)
- OCRによって取得できた文字列について、正規表現により番号を抽出
- CSVに出力
2.についてですが、こちらは番号をより認識しやすくするための処理です。
基本的に白黒の画像の方がOCRの精度が高くなります。
3.まで実行した結果の画像は以下の通りです。

上記の画像をTesseract OCRで文字認識することになります。
5.についてですが、例えばOCRした文字列が「012-345-6789」といつでも綺麗に取得できれば良いですが、「| 012-345-6789_」のように、場合によっては何か他のものが認識されてしまい、番号の形式にならないこともあります。
したがって、「XXX-XXX-XXXX」という形式の文字のみ抽出するようにします。それにより、例えばOCRの結果が「| 012-345-6789_」だったとしても、「012-345-6789」という結果を取得することができます。
以下が、これまでの手順を実行した結果のスクリーンショットです。
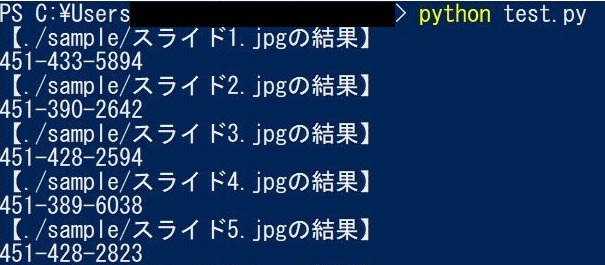
最終的には、上記結果をいい感じにcsvファイルにまとめるようになっています。
作成所感
PythonにはTesseract OCRを簡単に使用できるライブラリがあるので、プログラミングにかかる時間はそこまで大きくありませんでした。
ただ、結果は完璧というわけではなく、やはりTesseract OCRとはいえ誤認識が一定数あります。そこは最終的には手作業で修正する必要がありますね。
それでも作業時間は手入力するより大幅に減少すると思いますので、作業効率化には大きく貢献すると思います!
その他、OCRを使ったシステムをお考えの方は、お気軽にご連絡下さい。